Internship - Ways of Working
Project Structure
As these are short-term and remote projects we propose a minimum of weekly project “check-ins” with the NHS project supervisor (although more than often the frequency is higher than this). Regular code reviews & pair programming are encouraged as this increases the quality of code as well as ensuring the NHS supervisor understands the detailed progress of the work. These meetings will focus on technical specifics and hurdles.
More formal milestone meetings are also requested in order to run the project past the innovation team for wider comment. These meetings will focus on deliverables and project timeline and are usually monthly presented to a wider audience who are interested in the work.
It is expected at the beginning of the project that these milestones will be agreed between candidate and supervisor, and put in place to support monitoring of the project timelines, but should reflect releases of product / stages of the project where possible.

Apart from this we can be very flexible to accommodate the working style of the intern. Some projects have worked well with set work packages that are progressed in parallel. Other projects have preferred a more fluid approach with a minimum aim and then open avenues to explore as understanding increases. The main point is to ensure the intern is supported to deliver in a way suited to them whilst maintaining pace and an eye on the final deliverable.
Generally, we expect that the first couple of sprints are spent on background reading and scoping out the project (as well as some mandatory training). We also use this time for data access and environment setup. The project then usually moves to an exploratory phase before coming back to the project scope and finalising the main aims based off the exploration learning. The final couple of sprints should ensure that enough time is left for code tidy-up and write-up as we recognise the importance and time taken to generate materials that clearly describe the work and outcomes as well as creating open assets that others will be able to pick-up and run themselves.
Project Outputs
At the end of the project, we would look to have the following outputs alongside the codebase generated during the project:
Mandatory
- Project Code - The key output of the project is the code. We ask that where possible this code is made open through github. This github repo template is encouraged for interns to use. We will also ask all our interns to be aware of and follow our coding in the open guidance and checklists to ensure that the code released is appropriate.
- Technical Report - To enable a future user to understand the code and learning. Expect the reader to have some basic knowledge of the area and to have access to the repo with the final code in. Reference placeholders in the code and include code/project story to help reader understand the “why have they used this approach” as well as the what. Suggest around 2-pages per month but depends on project need.
- Project Overview Slides - around 10-20 slides with a focus on describing the project aims and achievements
Optional
- Experience Blog - Half page description of internship experience with learning/feedback. Optional to do this as a blog but we will need to capture some feedback please.
- Technical Blog - Focus on method/algorithm (e.g. Choice of sentiment library, VAE-DP, GPU requirements etc…) and acts as a stand alone explanation to others interested in the technique around it’s nuances and use.
- Recorded run through - To support others to understand the project a 5-min recorded demonstration or talk could be considered.
General Ways of Working
Github
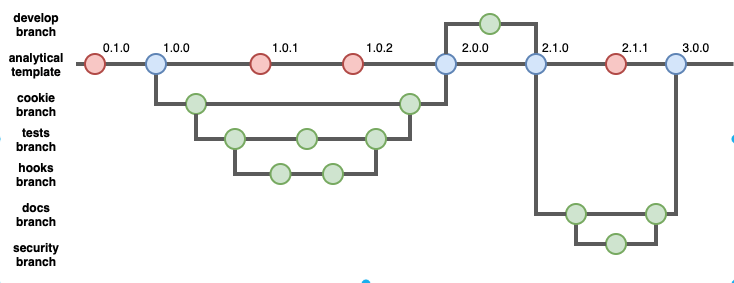
We use github as our main collaboration tool when the code is not sensitive. To support our work in github we use a standard project template with branches of this template including a more detailed cookiestructure, hooks for simple code quality checks, tests, MkDocs documentation, and docker setup.
These templates and branches are aimed at supporting gradual development of the codebase towards higher RAP standards as demonstrated by this example flow