Important: Disclaimer
This site is no longer active
Since August 2023 we have moved our content to a central Signpost Site
This is not the official site but a store of technical documents and ongoing work. Opinions expressed in posts are not representative of the views of NHS England and any content here should not be regarded as official output in any form. For more information about NHS England please visit our official website
DART Innovation Branch - Ways of Working
Github
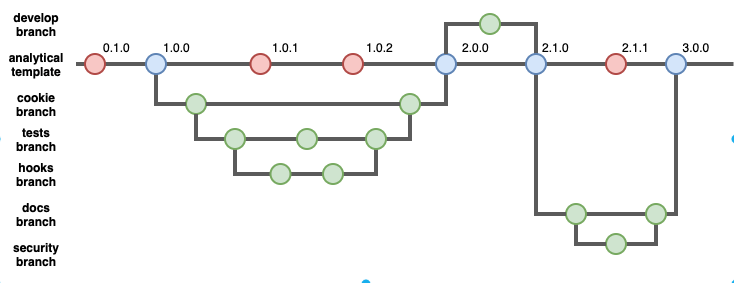
We use github as our main collaboration tool when the code is not sensitive. To support our work in github we use a standard project template with branches of this template including a more detailed cookiestructure, hooks for simple code quality checks, tests, MkDocs documentation, and docker setup.
These templates and branches are aimed at supporting gradual development of the codebase towards higher RAP standards as demonstrated by this example flow