Important: Disclaimer
This site is no longer active
Since August 2023 we have moved our content to a central Signpost Site
This is not the official site but a store of technical documents and ongoing work. Opinions expressed in posts are not representative of the views of NHS England and any content here should not be regarded as official output in any form. For more information about NHS England please visit our official website
Seasonal Papers
31st March 2023
To give us something to read over the many upcoming bank holidays we shared another set of recent three papers of interest.
Association Between Purchase of Over-the-Counter Medications and Ovarian Cancer Diagnosis in the Cancer Loyalty Card Study (CLOCS): Observational Case-Control Study
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9912145/
Paul highlighted a great example of using novel data sources and forecasting methods to create data-driven predictions for the diagnosis of Ovarian cancer. These predictions were based on the sales of over-the-counter pain and digestive medication eight to nine months prior to a diagnosis. The conclusion states “Facilitating earlier presentation among those who self-care for symptoms using this novel data source could improve ovarian cancer patients’ options for treatment and improve survival.”
Additionally, Paul recommended a book he’s currently reading, “We Are Electric” by Sally Adee. This describes the measurement of electric current in the body and of particular interest for us is the idea that different cell types have different detectable voltages. When a cell turns cancerous the voltage changes leading to the possibility of being able to diagnose and detect cancerous tissue. A podcast interviewing the author about these ideas can be found here
The Demonstrate-Search-Predict (DSP) Framework - Composing retrieval and language models for knowledge-intensive NLP
Dan brought us another paper from the world of language models this time focusing on a new retrieval-augmented in-context learning scheme called DSP. This approach aims to ground knowledge whilst still taking advantage of language models, by first obtaining examples of relevant materials to an initial question from a knowledge store via a retrieval model and then forming responses using a generative language model, in iterative steps (rather than a direct retrieve-then-read pipeline).
Users describe at a high-level how the problem to solve should be decomposed into smaller transformations in the DSP framework. An example program is given in the paper which given an input question and a 2-shot training set goes through the three stages of the learning cycle:
- Demonstrate stage programmatically annotates intermediate transformations on the training examples
- Learning from the resulting demonstration, the Search stage decomposes the complex input question and retrieves supporting information over two hops
- Predict stage uses the retrieved passages to answer the question.
The paper shows that building NLP systems with DSP can easily outperform GPT-3.5 by up to 120%.
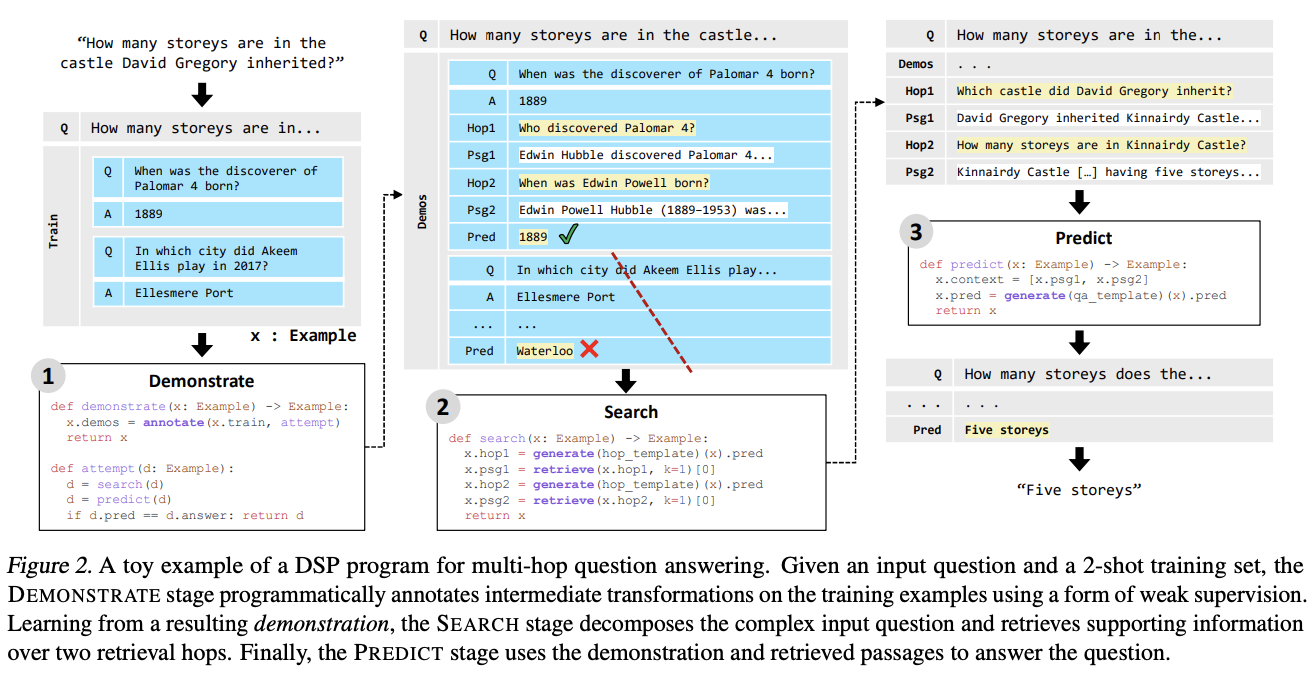
Figure taken from https://arxiv.org/abs/2212.14024
This technique is useful when embedded knowledge in model parameters or simple searches of a knowledge store may generate false assertions, whilst a task-aware DSP program systematically decomposes the problem and produces a correct response. The back and forth between a language model and retrieval model appear to be able to complete knowledge intensive natural language processing tasks which are common in healthcare. Additionally, the framework further allows for smaller models to be then “compiled” once a robust approach has been settled on, avoiding the need for retraining of massive models making this approach more accessible.
Process Mining – The issue of variability in healthcare
Finally, Jonny took us on a ramble through the issue of variability in process mining.
The paper Enhancing the usability and understanding of process mining in healthcare was created off the back of the of an international brainstorm [1] and resulting in specifying ten key recommendations for process mining in healthcare that need to be well considered.
RC-5 underlying indirect conditions on the process, the robustness for temporal changes and the ability to focus on infrequent behaviour.
A paper in BMJ Open titled “Can process mining automatically describe care pathways of patients with long-term conditions in UK primary care? A study protocol” states:
“The underlying processes are dynamic, complex, multidisciplinary, evolve as medical evidence develops and are frequently ad hoc.43 In the case of chronic illness, the patients’ interaction with the health service lasts for years. Taken together, these characteristics give rise to the problem of so-called ‘spaghetti’ models of un-interpretable complexity which contain so many nodes and interconnections that no useful structure or information can be inferred.”
Analysis of patient pathways with contextual process mining attempts to use a combination of community detection (clustering) based on known ontologies, network and process mining.
However, this still creates a final output that is essentially manual inspection and only deals with the spaghetti and rarity issues through data slicing.
The main paper of interest is the recent paper titled “Process mining for healthcare: Characteristics and challenges” generates a paper of healthcare specific points for process mining resulting in ten distinguishing characteristics and ten challenges for process mining in healthcare. We were particularly interested in the first four characteristics:
- Exhibit Substantial Variability – factors contributing to variability in healthcare include the vast diversity of activities, the fact that several subprocesses can occur simultaneously, and influence of personal preferences.
- Value the Infrequent Behaviour – infrequent behaviour is often considered as noise in many systems but in healthcare can be very valuable for identifying rare diseases and poor clinical outcomes.
- Use Guidelines and Protocols – Clinical Practice Guidelines (CPGs) bring required standardisations but also limitations in regards to D1 and D2
- Break the Glass – build and prepare for surges at a system level or individual emergencies
One component which we though was missing from the paper was an approach to calculating the distance between similar individual events and pathways. Two pathways can appear very similar at an event level but the ordering and wait in between the events may have a cataclysmic effect. At the same time vastly different routes through the same system may be inconsequential to the outcomes for the individual and system. Thus, careful consideration is required for these calculations in the conformance and enhancement stages.
Good background reading and a systematic review of healthcare process mining can be found in The Application of Process Mining to Care Pathway Analysis in the NHS
[1] The international brainstorm seminar took place on June 27th and June 28th, 2019 in Hasselt (Belgium). It was an initiative of the Process-Oriented Data Science for Healthcare Alliance (https://www.pods4h.com), supported by the Scientific Research Community on Process Mining (https://www.srcprocessmining.com)