Important: Disclaimer
This site is no longer active
Since August 2023 we have moved our content to a central Signpost Site
This is not the official site but a store of technical documents and ongoing work. Opinions expressed in posts are not representative of the views of NHS England and any content here should not be regarded as official output in any form. For more information about NHS England please visit our official website
Model Class Reliance for Demonstrating Variable Importance
One of our data science intern projects looked into applying a novel variable importance technique, MCR (model class reliance), to machine learning models in order to assess the Value of Commercial Product Sales Data in Healthcare Prediction. See the write up in the report folder.
Here, we’ll just focus on the variable importance component of the project and where else this technique could be used.
Variable Importance tools
Variable importance tools can, in the main, be broken down into three types: coefficient, decision split, or permutation.
- Coefficient feature importance investigates the model outputs from models such as linear or logistic regressions to see if the feature fits.
- Decision split feature importance attempts to minimise the split points for algorithms such as random forests, classification and regression trees of some stochastic gradient boosted algorithms.
- Permutation feature importance runs the same predictive model many times over different subsets of features and compares the predictive power to understand the mean importance score for each feature.
Whilst permutation techniques can be more resource intensive and require a performance metric to be defined, they are recommended as they are model agnostic, can be applied to complex or opaque models, and can be used to compare features across multiple models.
During the first phase of the project a standard permutation importance tool within the scikit-learn python library was used - the permutation importance function.
In addition to this a SHAP (SHapley Additive exPlanations) Analysis was completed, which attributes to each feature the change in the expected model prediction when conditioning on that feature.
By running these variable importance tools on one arbitrary model, misleading results can be given due to the stochastic nature of the model’s machine learning algorithms. This is a problem because different instances of an optimised model class can use different variables (features) and in different ways to achieve the same model predictive performance.
To address the problem of standard variable importance tools only evaluating one instance of a model, MCR (Model Class Reliance) was applied and compared.
Model Class Reliance
MCR was developed by Fisher et al. to compute the feature importance bounds across all optimal models called the Rashomon set for Kernel (SVM) Regression (polynomial run-time). Smith, Mansilla and Goulding introduced a new technique that extends the computation of MCR to Random Forest classifiers and regressors. This new technique is being developed as part of the UKRI CIVIC project.
MCR builds on permutation importance for a single model, computing the permutation feature importance bounds (MCR-, MCR+) for an input variable across all instances of the predictive model; calculating the minimum and maximum impact a variable could have on the predictions across all instances of the model.
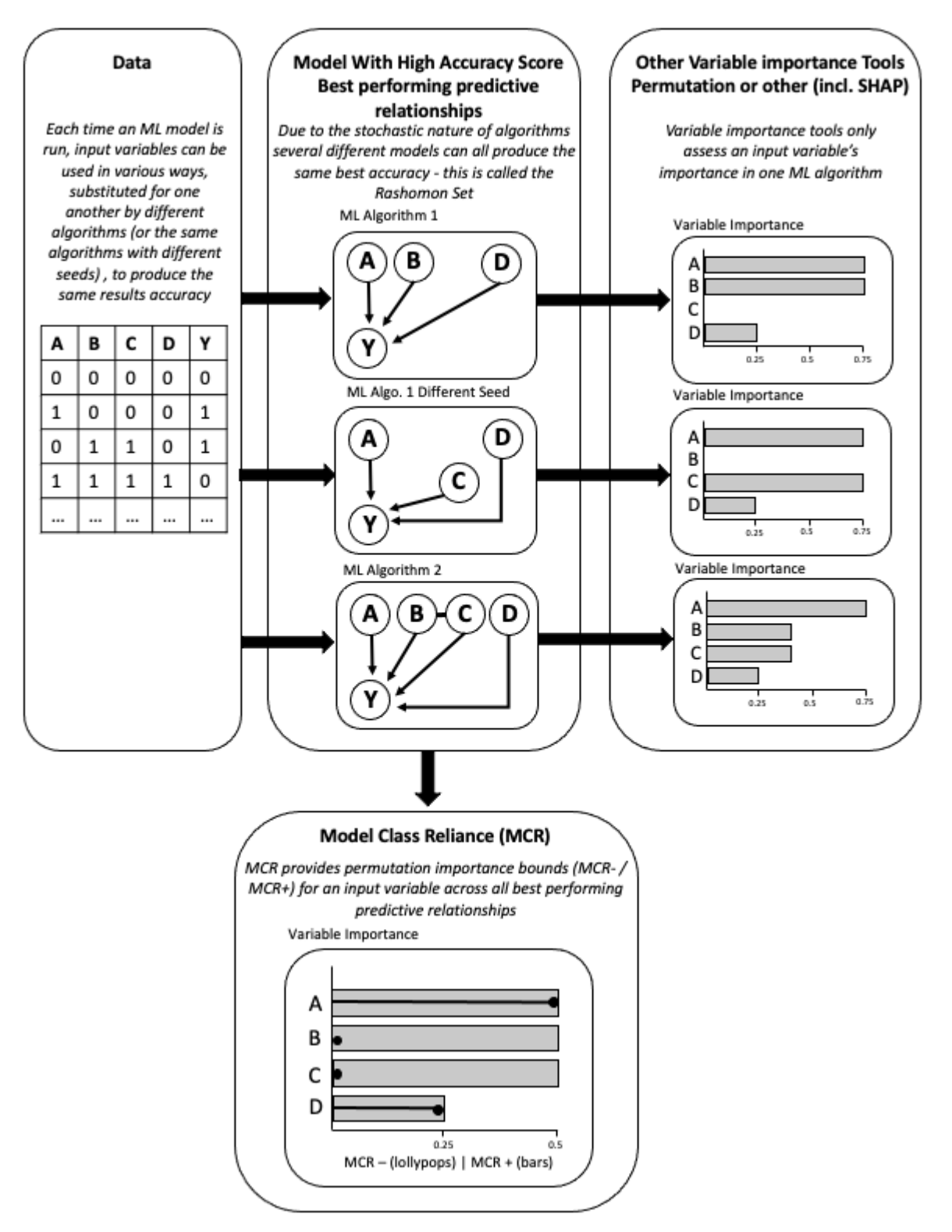
The base MCR analysis evaluates each feature individually for its importance, for example the importance of ‘minimum temperature’. It does not assess how important a dataset type used to create a number of the models’ features was to predictions as a whole, for example ‘weather’. A Group-MCR version has also been created in order to calculate the effects of variable groups, measuring the importance of a collection of features together on the predictions (See main project report for more details).
Use in Healthcare Predictions
MCR can be used to establish the value of using a variable in a model being created for healthcare predictions, by suggesting which data types must be acquired for a predictive model to work effectively. In a healthcare setting it must be considered whether it is worth the investment in acquiring a type of data if another dataset works equally well, and is more affordable, or easier to access. MCR highlights which data types could be irreplaceable and which could be interchangeable.
MCR results can also be used to guide the reduction of variables in order to create more transparent models for healthcare predictions.
GroupMCR offers us further information by implying how groups of variables may be working together in the model’s algorithms. By enabling the reduction of the number of variables, MCR can also be used to help decrease the dimensionality of the model leading to a more manageable global surface area to search for optimized meta-parameters. Creating the most accurate model possible using the chosen variables, would further evidence the value of their inclusion.